Medidas descriptivas en estadística: guía completa y ejemplos
Las medidas descriptivas son la base de la Estadística Descriptiva y, aunque suenen a algo muy técnico, en realidad las usamos a diario sin darnos cuenta. Cada vez que hablas de “nota media de un examen”, de “la mayoría de la gente prefiere…” o de que “hay mucha diferencia entre unos sueldos y otros”, estás utilizando, sin saberlo, ideas que tienen que ver con estas medidas.
En cualquier análisis de datos, ya sea en ciencias sociales, economía, salud o en el día a día de una empresa, necesitamos herramientas que nos ayuden a resumir, ordenar y entender grandes cantidades de información. Eso es exactamente lo que hacen las medidas descriptivas: condensan montones de números en unos pocos valores fáciles de interpretar, que nos permiten ver de un vistazo qué está pasando con las variables que estudiamos.
Qué son las medidas descriptivas y para qué sirven
Cuando hablamos de medidas descriptivas en estadística nos referimos a un conjunto de valores numéricos que se calculan a partir de los datos y que resumen distintos aspectos de su comportamiento. Estas medidas nos permiten responder preguntas del tipo: ¿cuál es el valor “típico”?, ¿cómo se agrupan los datos?, ¿hay mucha variabilidad?, ¿hasta qué punto se parecen entre sí las observaciones?
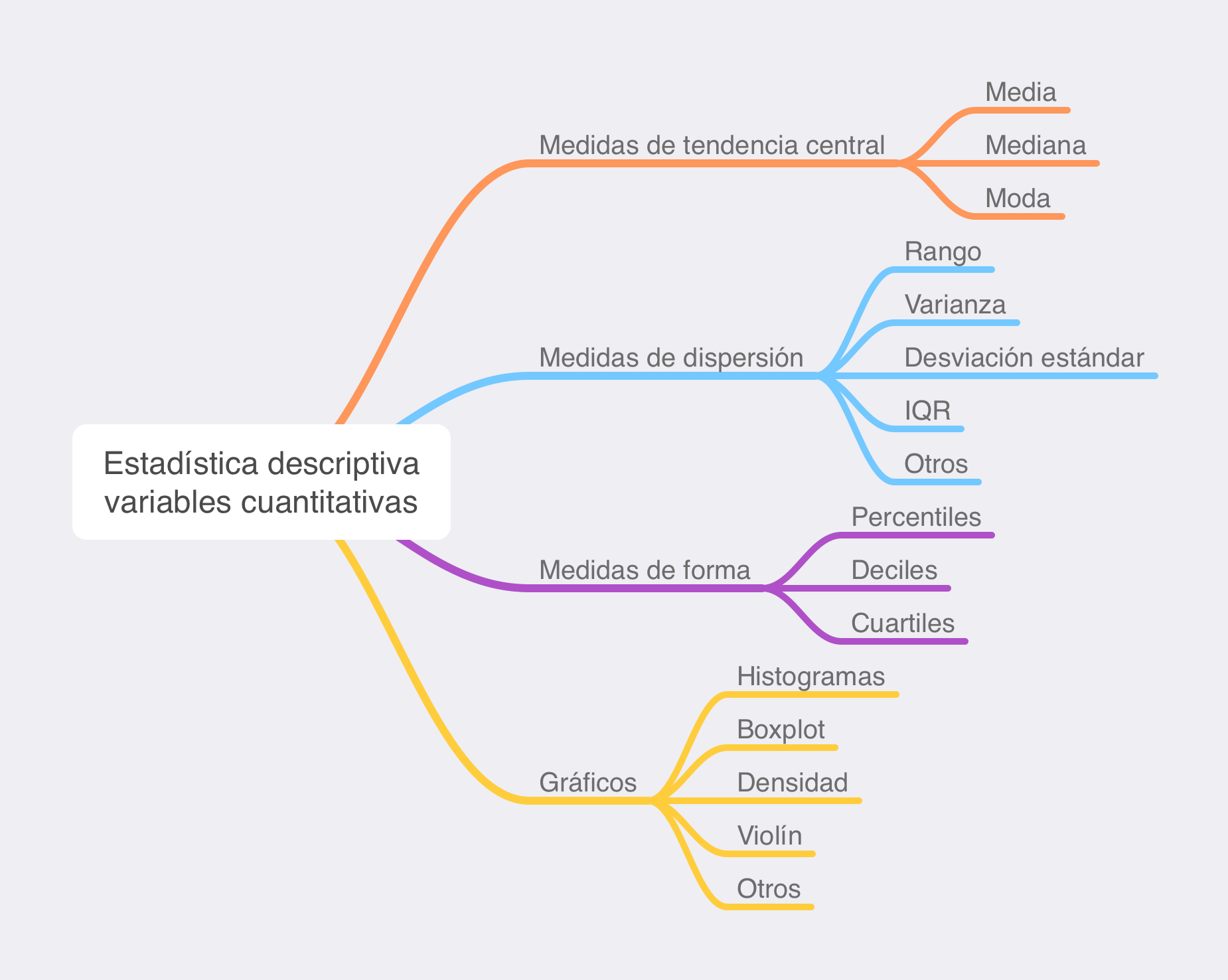
Para organizar esta tarea, las medidas descriptivas suelen agruparse en varias categorías: medidas de posición o tendencia central, que indican dónde “se sitúan” los datos; medidas de dispersión, que nos dicen cuánto se alejan unos de otros; y otras medidas complementarias, como los coeficientes relativos o algunas medidas de forma, que pueden ayudar a afinar el análisis.
En muchos apuntes y manuales universitarios, las medidas descriptivas aparecen acompañadas de ejemplos numéricos sencillos, como pequeños conjuntos de notas, sueldos o cantidades vendidas. Esto se debe a que la mejor manera de entender qué aportan cada una de estas medidas es ver cómo se calculan y qué información concreta nos dan sobre un conjunto amplio de observaciones.
Medidas de posición o tendencia central
Las medidas de posición o tendencia central nos indican qué valor puede considerarse más representativo de un conjunto de datos. Nos dan una idea de dónde se “concentran” las observaciones, o cuál sería, por así decirlo, el valor típico o central. Las más utilizadas son la media, la mediana y la moda, cada una con sus peculiaridades y usos recomendados.
Estas medidas se aplican tanto a datos sin agrupar (listados de valores individuales) como a datos agrupados en tablas de frecuencias. En los materiales de estadística de muchas universidades, se empieza explicando la versión más sencilla, a partir de un conjunto de valores X1, X2, …, Xn, para después generalizar a casos más complejos. Lo importante es entender qué representa cada medida y cuándo tiene sentido usarla.
Media muestral o promedio
La media muestral es probablemente la medida de tendencia central más conocida. Si tenemos n datos X1, X2, …, Xn, la media muestral es su media aritmética, es decir, la suma de todos los valores dividida entre el número total de observaciones. Es el famoso “promedio” del que se habla al comentar notas, salarios, tiempos de espera o cualquier otra magnitud cuantitativa.
Formalmente, si llamamos X̄ a la media muestral, se calcula como X̄ = (X1 + X2 + … + Xn) / n. En muchos apuntes se presenta esta definición de forma compacta, pero lo esencial es entender que la media reparte de manera uniforme la “cantidad total” entre todos los individuos. Por ejemplo, si sumamos las notas de un grupo de estudiantes y dividimos por el número de alumnos, obtenemos una nota media que nos indica el rendimiento general del grupo.
La media muestral tiene propiedades muy útiles, pero también un inconveniente importante: es muy sensible a valores extremos. Si dentro de un conjunto de datos hay un valor mucho más grande o mucho más pequeño que el resto, ese dato “arrastrará” la media hacia arriba o hacia abajo. Por eso, en situaciones en las que existen outliers muy marcados, puede que no sea la medida más adecuada para resumir la posición.
Moda muestral
La moda muestral es el valor que más se repite en el conjunto de datos. Se define como el dato con mayor frecuencia absoluta, es decir, aquel que aparece más veces. A diferencia de la media, no se obtiene mediante operaciones aritméticas, sino a partir de un recuento de cuántas veces se observa cada valor posible.
Un detalle importante es que la moda puede no existir o no ser única. Puede ocurrir que todos los valores sean distintos y ninguno se repita más de una vez; en ese caso, la distribución se dice amodal. También puede suceder que haya dos o más valores con la misma frecuencia máxima; entonces hablamos de distribuciones bimodales o multimodales, y se consideran varias modas simultáneamente.
La moda resulta especialmente útil cuando trabajamos con variables cualitativas o categóricas, en las que no tiene sentido calcular una media numérica. Por ejemplo, si queremos saber cuál es la preferencia mayoritaria entre varias opciones de respuesta, la moda nos dice qué categoría elige con más frecuencia la gente encuestada.
Mediana muestral
La mediana muestral es el valor que ocupa la posición central cuando ordenamos los datos de menor a mayor. Para obtenerla, primero se reordenan las observaciones, y después se localiza el dato del medio. Si el número de observaciones es impar, la mediana es exactamente ese valor central; si es par, se define como la media de los dos valores centrales.
En muchos ejemplos sencillos, se explican estos pasos de forma muy visual: se listan los datos, se ordenan, y se “tachan” por fuera hacia dentro hasta quedarnos con el que queda en el centro. De este modo se ve claramente que la mediana es el punto que divide la muestra en dos mitades: el 50 % de los datos queda por debajo y el otro 50 % por encima.
Un detalle interesante es que, a diferencia de la media, la mediana no se ve tan afectada por valores extremos. Si añadimos un valor muy grande o muy pequeño a un conjunto ordenado, es posible que la mediana apenas cambie, mientras que la media sí se desplaza de forma notable. Por eso, cuando existen outliers o la distribución es muy asimétrica, la mediana suele considerarse una medida más robusta de tendencia central.
Ejemplo de media, mediana y moda
En los materiales docentes suele aparecer un ejemplo análogo a este: se consideran los datos 3, 5, 7, 7, 8, 9 y se piden las principales medidas de posición. La media se calcula sumando todos los valores y dividiendo entre el número total de datos: (3 + 5 + 7 + 7 + 8 + 9) / 6 = 39 / 6 = 6,5. Así, la media muestral es 6,5, que sería el valor promedio del conjunto.
Si miramos la lista ordenada, vemos que los valores centrales son el tercero y el cuarto, que en este caso son 7 y 7. La mediana se obtiene tomando la media de estos dos valores, lo que da una mediana muestral igual a 7. Al estar repetidos, la mediana coincide exactamente con ese valor, que actúa como punto de equilibrio para el 50 % inferior y el 50 % superior.
Respecto a la moda, basta con fijarse en qué valor aparece más veces. En este ejemplo, el número 7 se repite dos veces, mientras que los demás aparecen una sola vez. Por tanto, la moda muestral también es 7. En este conjunto de datos se da la circunstancia de que mediana y moda coinciden, pero no es algo que ocurra siempre.
Este tipo de ejemplos numéricos sencillos son muy habituales en las presentaciones de Estadística Descriptiva y sirven para reforzar la idea de que cada medida de posición aporta un matiz distinto: la media describe el equilibrio global, la mediana la posición central resistente a valores extremos y la moda la categoría o valor más frecuente.
Medidas de dispersión
Además de saber cuál es el valor típico o central, interesa saber cómo de dispersos están los datos alrededor de esa posición. No es lo mismo que todas las observaciones estén muy juntas que que haya grandes diferencias entre unas y otras. Las medidas de dispersión cuantifican precisamente esa variabilidad, es decir, el grado de dispersión de los datos respecto a su tendencia central.
En los apuntes de estadística más básicos se presentan varias medidas de dispersión: el rango, la varianza, la desviación típica y el coeficiente de variación. Cada una nos aporta una forma distinta de ver cuánta diferencia hay entre los valores de una variable, y se utilizan de forma complementaria para tener una visión completa del comportamiento de los datos.
Rango
El rango es probablemente la medida de dispersión más simple de todas. Se define como la diferencia entre el valor máximo y el valor mínimo de los datos. Si ordenamos las observaciones de menor a mayor como X1 ≤ X2 ≤ … ≤ Xn, el rango se calcula como R = Xn − X1. Esta fórmula aparece con frecuencia en los materiales docentes como la primera aproximación a la idea de dispersión.
El rango nos da una información inmediata sobre la amplitud total de los datos: indica cuántas unidades separan el valor más pequeño del más grande. Sin embargo, tiene una limitación importante: solo depende de esos dos valores extremos y no tiene en cuenta cómo se distribuyen los datos intermedios. Por eso, aunque es útil como indicador rápido, suele complementarse con otras medidas más elaboradas.
Varianza
La varianza es una medida de dispersión que tiene en cuenta todas las observaciones y se basa en las diferencias cuadráticas respecto a la media. Intuitivamente, mide cuánto se alejan, en promedio, los datos de la media muestral. Cuanto mayor sea la varianza, más dispersos están los valores alrededor del promedio; cuanto menor, más concentrados.
En los apuntes de estadística se presenta la varianza con su definición formal, pero a la hora de calcularla se suele utilizar una fórmula equivalente más cómoda, que evita tener que trabajar directamente con todas las diferencias al cuadrado. Para datos muestrales, la varianza acostumbra a representarse por s² y, aunque no siempre se entra en todos los detalles teóricos en los niveles iniciales, se insiste en que se trata de una media de cuadrados de desviaciones respecto a la media.
Un aspecto a tener en cuenta es que la varianza se expresa en unidades al cuadrado. Por ejemplo, si la variable se mide en euros, la varianza se mide en euros cuadrados, lo cual no tiene una interpretación directa tan intuitiva. Este es uno de los motivos por los que suele preferirse la desviación típica, que devuelve la medida a las unidades originales.
Desviación típica o estándar
La desviación típica, también llamada desviación estándar, es la raíz cuadrada de la varianza. De este modo, si la varianza muestral es s², la desviación típica es s. Al tomar la raíz cuadrada, se vuelve a las unidades originales de la variable, lo que hace que esta medida sea mucho más fácil de interpretar en la práctica.
En la docencia universitaria de estadística se recalca que la desviación típica no debe confundirse con el error típico o error estándar. Aunque los nombres se parecen, el error estándar es un concepto de Estadística Inferencial relacionado con la variabilidad de un estimador, mientras que la desviación típica es una medida de la dispersión de los datos dentro de la muestra. Esta aclaración suele remarcarse con expresiones como “ojo, no confundir” para evitar malentendidos.
La desviación típica nos dice, de forma aproximada, cuánto se separan los datos de la media. En muchas distribuciones, una proporción importante de las observaciones se sitúa dentro del intervalo comprendido entre la media menos una desviación típica y la media más una desviación típica. Por eso, esta medida es fundamental a la hora de evaluar la estabilidad o variabilidad de los datos en numerosos contextos.
Coeficiente de variación
El coeficiente de variación es una medida de dispersión relativa que relaciona la desviación típica con la media. Aunque la expresión exacta puede variar según la convención, suele definirse como el cociente entre la desviación típica y la media, a menudo multiplicado por 100 para expresarlo en porcentaje. Es una herramienta útil cuando queremos comparar la variabilidad de distintas variables que tienen medias muy diferentes o unidades distintas.
Por ejemplo, si comparamos salarios en dos sectores con diferentes escalas, puede ocurrir que un sector tenga una desviación típica mayor en términos absolutos, pero un coeficiente de variación menor, lo que indicaría que, proporcionalmente, los salarios están más concentrados alrededor de su media. En ese sentido, el coeficiente de variación resulta especialmente interesante para analizar la dispersión de forma relativa, más allá de las unidades concretas de medida.
Relación entre medidas de posición y dispersión
En un análisis de datos mínimamente serio, no tiene sentido quedarse solo con la media o solo con la desviación típica. Lo habitual es combinar medidas de posición y de dispersión para obtener una visión más rica. Por ejemplo, podemos tener dos grupos con la misma media pero con varianzas muy distintas; en ese caso, aunque el valor central sea el mismo, la realidad de cada grupo es muy diferente.
Las medidas de posición nos dicen en qué entorno se mueven los datos, mientras que las de dispersión aclaran cómo se reparten alrededor de ese entorno. Una media alta con poca dispersión indica un grupo homogéneo con valores elevados; una media similar con mucha dispersión refleja grandes diferencias entre las observaciones individuales. Por eso, en la práctica, las tablas y resúmenes estadísticos suelen incluir siempre, al menos, una medida de tendencia central y una de variabilidad.
En los materiales de Estadística Descriptiva de diversas universidades aparece con frecuencia la estructura: definición de la variable, tabla de frecuencias, representación gráfica, cálculo de media, mediana, moda y, a continuación, rango, varianza, desviación típica y coeficiente de variación. Esta secuencia de trabajo refleja la idea de que las medidas descriptivas forman un bloque coherente que permite entender los datos desde varios ángulos complementarios.
Además, a medida que se profundiza en la materia, pueden introducirse otras medidas relacionadas, como los percentiles, cuartiles o medidas de asimetría y curtosis, que amplían el análisis descriptivo. No obstante, el núcleo fundamental que se explica en los primeros temas de estadística suele estar formado precisamente por las medidas de posición y las de dispersión que hemos comentado.
Todo este conjunto de herramientas tiene una utilidad práctica muy clara: facilitar la toma de decisiones basada en datos. Ya sea en el ámbito universitario, en la administración pública o en una empresa privada, conocer la posición y la variabilidad de una variable clave ayuda a interpretar correctamente la información disponible y a evitar conclusiones precipitadas.
La Estadística Descriptiva, y dentro de ella las medidas descriptivas, permiten transformar listas interminables de números en unos pocos indicadores que resultan manejables e intuitivos. Gracias a media, mediana, moda, rango, varianza, desviación típica y coeficientes relativos, podemos hacernos una idea muy precisa de cómo se comportan los datos, detectar patrones, identificar anomalías y sentar las bases para análisis más avanzados si son necesarios.




{kind=link}